Two Agents, One MCP Server: Using a Second Claude as a Harness for the First
A few months ago I built a small personal self-service portal - one of its features is Polish PIT-38 tax calculation from raw IBKR / XTB / Dif broker exports. FIFO matching, NBP currency rates, dividend section, the works. I built it with Claude Code, in the way most people build with Claude Code now: I described what I wanted, the agent wrote the code, I reviewed and pushed.
The thing nobody talks about enough: when an agent writes the code, your tests are also code an agent wrote. If both lean on the same misreading of the spec, you don’t notice until tax time.
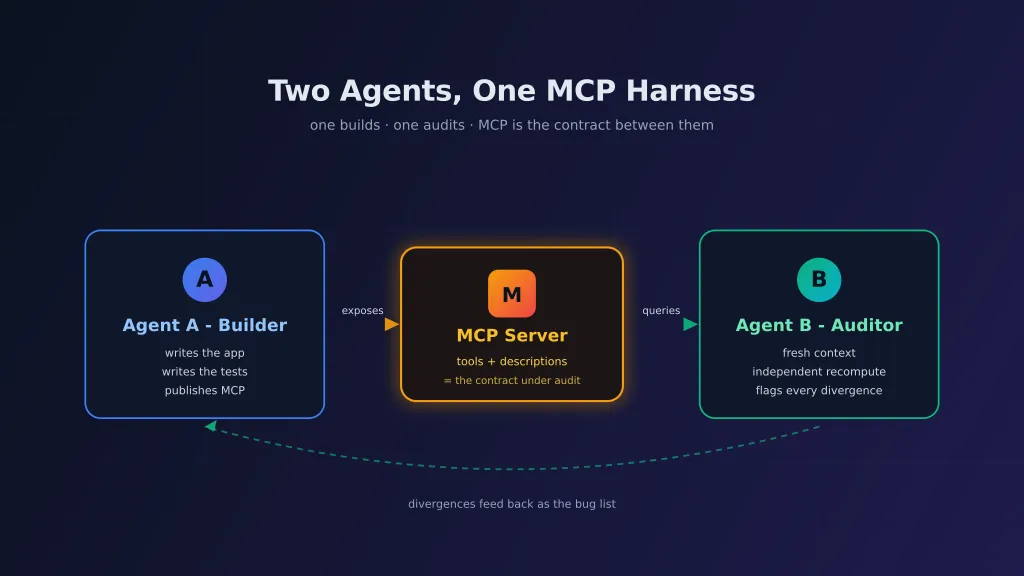
This post is about the loop I ended up using to catch that. One agent builds the app and exposes an MCP server describing its own outputs. A second agent - fresh context, no memory of the build - uses that MCP plus the raw broker files to independently re-derive the numbers. Where the two diverge, that’s the bug list.
It found a handful of real bugs. None of them small.
What “harness engineering” means
I first heard the term from Mitchell Hashimoto - HashiCorp co-founder (Terraform, more recently Ghostty) - in his interview on the new way of writing code. His thesis, paraphrased: traditional tests cover one happy case + one edge case + one bad case, which was fine when a human held the actual problem in their head. AI agents are goal-oriented - if there isn’t a spec or a test saying “this also matters”, they will cheerfully break it on the way to their goal. The agent has no engineering “intuition” - it respects only what is hard-coded.
His proposed fix: harness engineering. Every time you see an AI do something wrong, build a tool - a piece of the harness - that the agent can call to prevent or correct it. Shift effort from the product itself to the rig around the product.
The piece I want to add: the harness doesn’t have to be deterministic. A second agent, given the right interface and the raw ground truth, is a harness. MCP turns out to be an excellent way to wire that harness in.
The setup
%%{init: {'flowchart': {'nodeSpacing': 70, 'rankSpacing': 110, 'padding': 20}, 'themeVariables': {'fontSize': '20px'}}}%%
graph TD
A["Agent A
builds, exposes MCP"]
MCP["MCP server
= contract under audit"]
Raw["Raw broker CSVs
ground truth"]
B["Agent B
recomputes, prompted as
tax accountant"]
Me["Me
tiebreaker"]
A -->|publishes| MCP
MCP -->|queried by| B
Raw -->|fed to| B
B -->|deltas| Me
Me -.->|fix loop| A
classDef agent fill:#1e293b,stroke:#3b82f6,color:#e2e8f0,stroke-width:2px
classDef audit fill:#1e293b,stroke:#10b981,color:#e2e8f0,stroke-width:2px
classDef mcp fill:#1c1917,stroke:#f59e0b,color:#fcd34d,stroke-width:2px
classDef raw fill:#0f172a,stroke:#475569,color:#cbd5e1,stroke-width:1.5px
classDef me fill:#1e293b,stroke:#fbbf24,color:#fde68a,stroke-width:2px
class A agent
class B audit
class MCP mcp
class Raw raw
class Me meAgent A wrote the backend (Hono on Cloudflare Workers + D1 + KV), the TanStack Start frontend (why I picked this stack), and an MCP server that exposes endpoints like tax_get_year_summary({ year, includeGroups: true }). Each tool description tells a model what fields it returns and what they mean. That description is what the second agent reads to decide what to verify.
Agent B was a separate Claude Code session. It got two things:
- The raw IBKR / Dif / XTB statements I had on disk.
- A connection to the running MCP server.
I asked it: “compute the 2023, 2024 and 2025 PIT-38 values from the raw files independently. Then call the MCP server for the same years. Tell me where they disagree.”
That was it. No hand-holding about which functions to look at, no “check this file”. It read the MCP descriptions, looked at the broker formats, did its own FIFO, and then started flagging deltas.
Bug #1 - Cost basis at the wrong currency rate
This is the one that mattered most for actual tax owed.
PIT-38 is denominated in PLN, but trades happen in USD/EUR/etc. Polish tax law (art. 11a ust. 2 PIT) is unambiguous: revenue from a sale uses the NBP mid rate from D-1 of the sale, and cost basis uses the NBP mid rate from D-1 of each individual purchase. For a FIFO match where one sale eats five different lots bought across three years, that’s five different historical buy rates plus one sell rate.
What the app actually did:
// backend/src/routes/tax-calculator.ts (before)
const revenuePln = first.sellPrice * totalQuantity * rateInfo.rate;
const costPln = groupRows.reduce((sum, r) => {
return sum + (r.buyPrice * r.quantity + r.buyCommission + r.sellCommission)
* rateInfo.rate; // ← sell-day rate applied to every buy lot
}, 0);rateInfo.rate is the rate from D-1 of the sale. The reducer used that same rate for every lot in the FIFO group - including lots bought years earlier at very different USD/PLN rates.
USD/PLN went from ~4.85 in late 2022 to ~3.93 in late 2023. If you bought at 4.85 and sold at 3.93, the real PLN cost is higher than the PLN revenue - you have a tax loss in PLN even though the USD numbers look flat. The app valued the cost at the sell-day rate, which made the cost smaller in PLN than it should be, which made the PLN profit look bigger, which would have generated a fictitious tax bill.
Agent B caught this by noticing that for every multi-year FIFO group it ran, app cost basis was lower than its independent calculation by exactly the ratio of the two NBP rates. Across 2023–2025 the app over-stated profit by roughly 65,000 PLN cumulatively - about 8,800 PLN of tax that wasn’t actually owed, plus a 2023 loss the app failed to recognise (which would normally carry forward and offset future gains).
Agent A’s fix was the obvious one once you’ve seen it: pre-fetch all the (currency, date) pairs needed across both buy and sell legs, build a Map, and look up per-lot at FIFO time. After the fix, my independent recomputation matches the app to the grosz on the IBKR delta, with a ~500 PLN/year residual on the Dif broker - and that residual turned out to be the app correctly including monthly custody fees that my hand calc hadn’t picked up. The app was now more right than I was.
Bug #2 - Dividend rows had price = 0
The IBKR dividend totals from the API were coming back at 0 PLN for 2023 - which is impossible if there were dividends at all.
The IBKR dividend parser:
// backend/src/lib/parsers/ibkr-dividends.ts (before)
case 'Dividends':
type = TransactionType.Dividend;
amount += Math.abs(d.amount); // sets amount
hasValidTransactions = true;
break;Compare with the sibling case for broker interest in the same file:
case 'Broker Interest Received':
symbol = 'IBKR Interest';
quantity = 1;
type = TransactionType.OtherFees;
price += Math.abs(d.amount); // sets price ← !The dividend case set amount but never set price. Downstream, FIFO computes grossFx = sellPrice × quantity to derive the dividend totals. With price = 0 and quantity = 0 it dutifully produced grossFx = 0 for every dividend row, which propagated all the way to the PLN dividend totals returned over MCP.
Why this passed the existing tests: the parser test asserted on amount and fee but not on price. Classic “test coverage ≠ test adequacy”. The harness loop caught it because Agent B was comparing computed PLN dividend totals against the broker’s own statement totals - and the totals from the API were flatly wrong, while tax_get_year_summary happily returned a non-zero withholding-tax total (parsed correctly via a different code path), which is what made the bug pattern even visible.
Three lines of fix, plus a regression test seeded with the actual AVGO and MSFT dividend rows from my real CSV, plus a SQL backfill to retroactively repair existing data:
UPDATE transactions
SET price = amount, quantity = 1
WHERE broker = 'IBKR' AND type = 'Dividend' AND price = 0 AND amount > 0;Why MCP is the right harness interface
You could imagine doing this audit a few different ways. You could ask Agent B to read the source code directly. You could expose a giant SQL dump and let it grep. You could write a separate “verifier” CLI.
MCP is better than any of those for one reason: it forces the description.
Every MCP tool comes with a natural-language schema: what it does, what it returns, what each field means. To expose your code over MCP at all, you have to write that down. And the moment you write it down, you’ve created a contract that a second agent can audit against the ground truth. The auditor doesn’t need to read your code. It needs to read your description and compare what you claim against what an independent computation says.
There’s another class of bug I hit that I haven’t written up here in detail: the math was internally consistent, but the field labels lied about which line of the official tax form they corresponded to. That kind of bug is only findable through external description-vs-truth comparison. No amount of unit testing inside the build agent’s session would have caught it, because the build agent was the one who wrote both the tests and the labels.
What I’m describing has a name in older literature: differential testing. Compiler people use it constantly - csmith generates random C programs and feeds them to GCC, Clang and LLVM; whenever the outputs disagree, at least one compiler has a bug. Its sibling is property-based testing (QuickCheck, Hypothesis): generate inputs, assert invariants hold across all of them. The MCP harness is differential testing where the second implementor is an LLM and the spec under test is the MCP tool description. The technique is from 1998. The fresh part is that you no longer need to hand-write the second implementation - you prompt for it.
This is what makes MCP a natural fit for harness engineering: the tool description is the contract, and a second agent is a cheap, parallelisable contract auditor.
When the auditor itself is wrong
The obvious objection: what if Agent B’s independent FIFO is itself buggy? Then I’d have two implementations disagreeing and no way to know which one is closer to the truth.
In practice this didn’t happen, and I think the reason is the prompt. Agent B wasn’t a blank Claude Code session given raw CSVs and told “go”. Its system prompt cast it as an experienced Polish tax accountant who has done PIT-38 reconciliations against IBKR / XTB exports many times before, knows the relevant articles of the PIT law by reference, and treats the NBP rate table as authoritative. That framing matters. An auditor with domain authority asks better clarifying questions (“mid rate or fix rate? D-1 banking day or D-1 calendar day?”), references the right law (art. 11a ust. 2), and is far less likely to invent a plausible-looking but spec-violating shortcut. The prompt was doing real work.
But “didn’t happen” is not “can’t happen”. The loop is two-out-of-three, not two-out-of-two. When A and B disagree, I sit down with the official spec and the raw CSV and decide. On Bug #1 I literally wrote the FIFO out in a spreadsheet myself before I trusted either agent - the sanity check where my hand calc matched the app to the grosz, with a ~500 PLN/year residual that turned out to be the app being more right than me, is what closed the loop. I’m the tiebreaker, and the pattern degrades sharply if you take it to a domain you don’t understand cold.
The fix loop is iterative, not one-shot: A patches, redeploys the MCP server, B re-runs its comparison, deltas drop or shift to expose the next layer. Bug #2 only became visible after Bug #1 was fixed.
Where this doesn’t work
This loop has a hard prerequisite: an independent ground truth that a second agent can re-derive from inputs you also hold. Where that prerequisite breaks, the harness doesn’t help:
- No external ground truth. Pure UI work, internal workflows, anything where “correct” is not defined outside the app itself. There is nothing for Agent B to recompute to.
- Side effects as the output. Sending emails, charging cards, mutating external state. You cannot ask a second agent “what should have happened” because the action was the spec, and replaying it has its own consequences.
- Many valid answers. Summarisation, copywriting, UX decisions. Agent B disagreeing with Agent A is just two opinions, not a bug list.
- Non-numeric contracts. Animations, layout, rendering. The “correct” output isn’t expressible as a function call return value the second agent can independently produce.
PIT-38 worked because the spec is a PDF, the inputs are CSV, and the output is a number. Most apps are not that lucky. The harness pattern is strongest at the boundary where deterministic computation meets external authority - financial calculations, format converters, data pipelines with reference outputs, parsers with published grammars.
What I changed about how I work
Four things stuck after this experiment.
1. The build agent must publish an MCP server, even for “internal” apps. I had originally exposed MCP because I wanted my Claude Code sessions to be able to query my own tax data. The audit use case was a happy accident. I now treat it as the primary reason: if there’s no MCP, there’s no harness surface, and I’m flying blind on AI-written code.
2. The audit agent gets the raw inputs, not the code - and a domain-expert prompt. When I ran Agent B I deliberately did not show it tax-calculator.ts. I showed it the IBKR / Dif / XTB CSVs and the MCP connection, and I cast it explicitly as an experienced Polish tax accountant with PIT-38 / FIFO / NBP-rates knowledge baked into the system prompt. Both halves matter. No code, so the auditor doesn’t pattern-match its way into the same misunderstanding. Domain authority in the prompt, so it knows which questions to ask before running a single line.
3. MCP description changes are versioned like API changes. When I fixed a labelling bug where only the field semantics changed and the wire format was identical, I still bumped MCP_SERVER_VERSION from 1.1.0 to 1.2.0. A downstream agent has to know its prior reading of the world is invalid, and version is the signal.
4. There is always a human tiebreaker. Two agents disagreeing is not a verdict, it’s an alarm. The arbiter is me with the spec next to me - and on the bug that mattered most, I literally re-did the FIFO in a spreadsheet. The loop is A ↔ B ↔ human, not A ↔ B. Drop the human and you get a pair of confidently-wrong agents pointing at each other.
What this isn’t
I’m not claiming a second agent replaces tests. The unit tests still exist, still run in CI, still catch regressions in seconds. That’s the deterministic harness - it’s fast, cheap, and ungameable.
The second-agent audit is a slower, more expensive layer that catches a different class of bug: the ones where the tests and the code agree because they share an authorial misunderstanding. Those bugs don’t surface in a green CI run. They surface when something outside the bubble - the official PIT-38 form, the broker’s own statement totals, a friend doing it in Excel - disagrees with the bubble. MCP is just the cheapest way I’ve found to plug “outside the bubble” into the loop.
If Hashimoto is right that testing fundamentally has to change in the AI era, my small data point from one personal project is: yes, and the change looks like building APIs the next agent can audit you with. The MCP server isn’t there to make your app extensible. It’s there so the next agent doesn’t have to trust you.

Senior Site Reliability Engineer